The ABC’s of Splunk Part Three: Storage, Indexes, and Buckets

In our previous two blogs, we discussed whether to build a clustered or single Splunk environment and how to properly secure a Splunk installation using a Splunk user.
For this blog, we will discuss the art of Managing Storage with indexes.conf
In my experience, it’s easy to create and start using a large Splunk environment, until you see storage on your Splunk indexers getting full. What would you do? You start reading about it and you get information about indexes and buckets but you really don’t know what those are. Let’s find out
What is an Index?
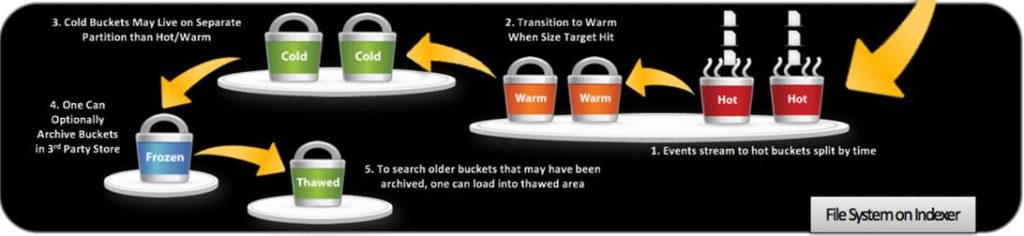
Indexes are a logical collection of data. On disk, index data is stored in different buckets
What are Buckets?
Buckets are sets of directories that contain _raw data (logs), and indexes that point to the raw data organized by age
Types of Buckets:
There are 4 types of buckets in the Splunk based on the Age of the data
- Hot Bucket
- Location – homePath (default – $SPLUNK_DB//db)
- Age – New events come to these buckets
- Searchable – Yes
- Warm Buckets
- Location – homePath (default – $SPLUNK_DB//db)
- Age – Hot buckets will be moved to Warm buckets based on multiple policies of Splunk
- Searchable – Yes
- Cold Bucket
- Location – coldPath (default – $SPLUNK_DB//cold)
- Age – warm buckets will be moved to Cold buckets based on multiple policies of Splunk
- Searchable – Yes
- Frozen Bucket (Archived)
- Location – coldToFrozenDir (default – $SPLUNK_DB//cold
- Age – Cold buckets can be optionally archived. Archived data are called to be Frozen buckets.
- Searchable – No
- Thawed
BucketLocation- Location – thawedPath (no default)
- Age – Splunk does not put any data here. This is the location where archived (frozen) data can be unarchived -we will be covering this topic at a later date
- Searchable – Yes
Manage Storage and Buckets
I always like to include the reference materials from which the blog is based upon and the link below has all the different parameters that can be altered whether they should or not. It’s a long read but necessary if you intend to become an expert on Splunk
https://docs.splunk.com/Documentation/Splunk/8.0.5/Admin/Indexesconf
Continuing with the blog:
Index level settings
- homePath
- Path where hot and warm buckets live
- Default – $SPLUNK_DB//db
- MyView – As data in Warm and hot bucket are latest and that’s what mostly is being searched. Keep it in a faster storage to get better search performance.
- coldPath
- Path where cold buckets are stored
- Default – $SPLUNK_DB//colddb
- MyView – As Splunk will move data from the warm bucket to here, slower storage can be used as long as you don’t have searches that span long periods > 2 months
- thawedPath
- Path where you can unarchive the data when needed
- Volume reference does not work with this parameter
- Default – $SPLUNK_DB//thaweddb
- maxTotalDataSizeMB
- The maximum size of an index, in megabytes.
- Default – 500000
- MyView – When I started working with Splunk, I left this field as-is for all indexes. Later on, I realized that the decision was ill-advised because the total number of indexes multiplied by the individual size, far exceeded my allocated disk space. If you can estimate the data size in any way, do it at this stage and save yourself the headache
- repFactor = 0|auto
- Valid only for indexer cluster peer nodes.
- Determines whether an index gets replicated.
- Default – 0
- MyView – when creating indexes (on a cluster), set the repFactor = auto so that if you change your mind down the line and decide to increase your resiliency. You can simply edit from the GUI and the change will apply to all your indexes without making manual changes to each one
And now for the main point of this blog: How do I control the size of the buckets in my tenancy?
Option 1: Control how buckets migrate between hot to warm to cold
Hot to Warm (Limiting Bucket’s Size)
- maxDataSize = |auto|auto_high_volume
- The maximum size, in megabytes, that a hot bucket can reach before splunk
- Triggers a roll to warm.
- auto – 750MB
- auto_high_volume – 10GB
- Default – auto
- MyView – Do not change it.
- maxHotSpanSecs
- Upper bound of timespan of hot/warm buckets, in seconds. Maximum timespan of any bucket can have.
- This is an advanced setting that should be set with care and understanding of the characteristics of your data.
- Default – 7776000 (90 days)
- MyView – Do not increase this value.
- maxHotBuckets
- Maximum number of hot buckets that can exist per index.
- Default – 3
- MyView – Do not change this.
Warm to Cold
- homePath.maxDataSizeMB
- Specifies the maximum size of ‘homePath’ (which contains hot and warm buckets).
- If this size is exceeded, splunk moves buckets with the oldest value of latest time (for a given bucket) into the cold DB until homePath is below the maximum size.
- If you set this setting to 0, or do not set it, splunk does not constrain the size of ‘homePath’.
- Default – 0
- maxWarmDBCount
- The maximum number of warm buckets.
- Default – 300
- MyView – Set this parameter with care as the number of buckets is very arbitrary based on a number of factors.
Cold to Frozen
When to move the buckets?
- frozenTimePeriodInSecs [Post this time, the data will be deleted]
- The number of seconds after which indexed data rolls to frozen.
- Default – 188697600 (6 years)
- MyView – If you do not want to archive the data, set this parameter to time for which you want to keep your data. After that Splunk will delete the data.
- coldPath.maxDataSizeMB
- Specifies the maximum size of ‘coldPath’ (which contains cold buckets).
- If this size is exceeded, splunk freezes buckets with the oldest value of the latest time (for a given bucket) until coldPath is below the maximum size.
- If you set this setting to 0, or do not set it, splunk does not constrain the size of ‘coldPath’.
- Default – 0
What to do when freezing the buckets?
- Delete the data
- Default setting for Splunk
- Archive the data
- Please note – If you archive the data, Splunk will not delete the data automatically, you have to do it manually.
- coldToFrozenDir
- Archive the data into some other directories
- This data is not searchable
- It cannot use volume reference.
- coldToFrozenScript
- Script that you can use to ask Splunk what to do to archive the data from cold storage
- See indexes.conf.spec for more information
- coldToFrozenDir
Option 2: Control the maximum volume size of your buckets
Volumes
There are only two important settings that you really need to care about.
- path
- Path on the disk
- maxVolumeDataSizeMB
- If set, this setting limits the total size of all databases that reside on this volume to the maximum size specified, in MB. Note that this will act only on those indexes which reference this volume, not on the total size of the path set in the ‘path’ setting of this volume.
- If the size is exceeded, splunk removes buckets with the oldest value of the latest time (for a given bucket) across all indexes in the volume, until the volume is below the maximum size. This is the trim operation. This can cause buckets to be chilled [moved to cold] directly from a hot DB, if those buckets happen to have the least value of latest-time (LT) across all indexes in the volume.
- MyView – I would not recommend using this parameter if you are having multiple (small and large) indexes in the same volume because now, the size of the volume will decide when the data moves from the hot buckets to the cold buckets irrespective of how important and or fast you need it to be
The Scenario that led to this blog:
Issue
One of our clients has a clustered environment and the hot/warm paths were on SSD drives of limited size (1 TB per indexer) and the coldpath had a 3TB size per indexer. The ingestion rate was somewhere around 60 GB per day across 36+ indexes which resulted in the hot/warm volume to fill up before any normal migration process would occur. When we tried to research the problem and ask the experts, there was no consensus on the best method and I would summarize the answer as follows “It’s an art and different per environment. I.e. we don’t have any advice for you”
Resolution
We initially started looking for an option to move data to cold storage when data reaches a certain age (time) limit. But there is no way to do that. (Reference – https://community.splunk.com/t5/Deployment-Architecture/How-to-move-the-data-to-colddb-after-30-days/m-p/508807#M17467)
So, then we had two options as mentioned in the Warm to Cold section.
- maxWarmDBCount
- homePath.maxDataSizeMB
The problem with the maxDataSizeMB setting is that it would impact all indexes which means that some are going to end up in the cold bucket although they are needed in the hot/warm bucket and are not taking space. So we went the warm bucket route because we knew that only three indexes seem to consume most of the storage. We looked at those and found that they were containing 180+ warm buckets.
We reduced maxWarmDBCount to 40 for these large indexes only and the storage size for the hot and warm buckets normalized for the entire environment.
For our next blog, we will be discussing how to archive and unarchive data in Splunk
Written by Usama Houlila.
Any questions, comments, or feedback are appreciated! Leave a comment or send me an email to uhoulila@newtheme.jlizardo.com for any questions you might have.
If you wish to learn more, click the button below to schedule a free consultation with Usama Houlila.