Security Incident handling with Splunk – Our new Cyences App published on Splunkbase


Macros
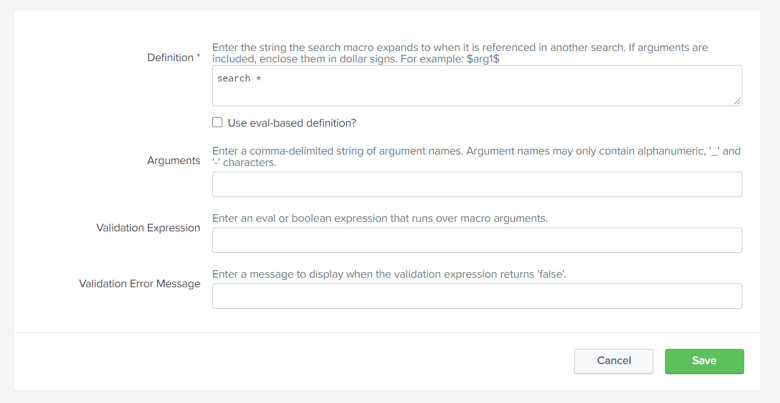
What are macros?
Search macros are reusable chunks of Search Processing Language (SPL) that you can insert into other searches. Search macros can be any part of a search, such as an eval statement or search term, and do not need to be a complete command. You can also specify whether the macro field takes any arguments.
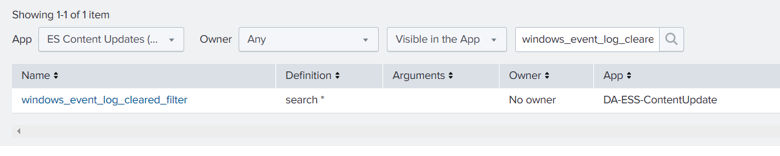
How to find/update the macro definition
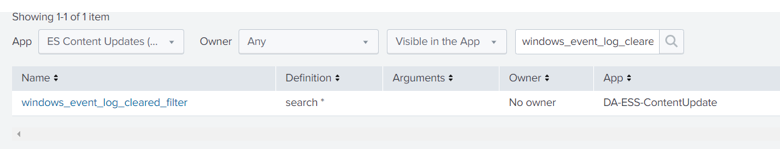

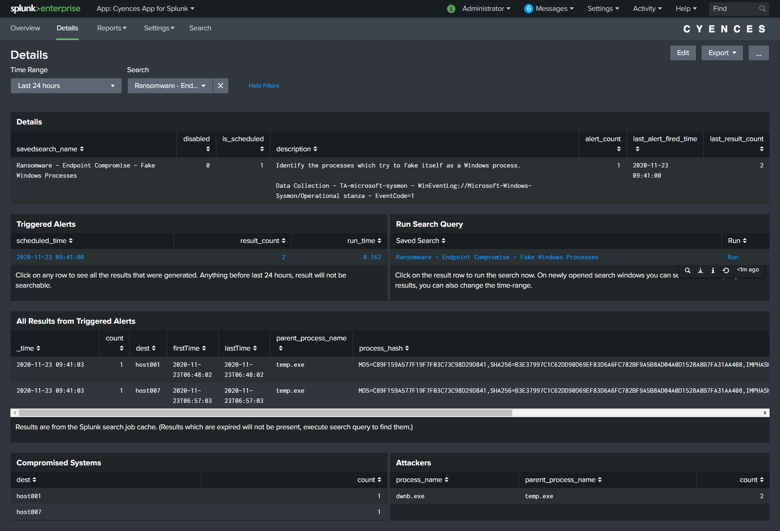
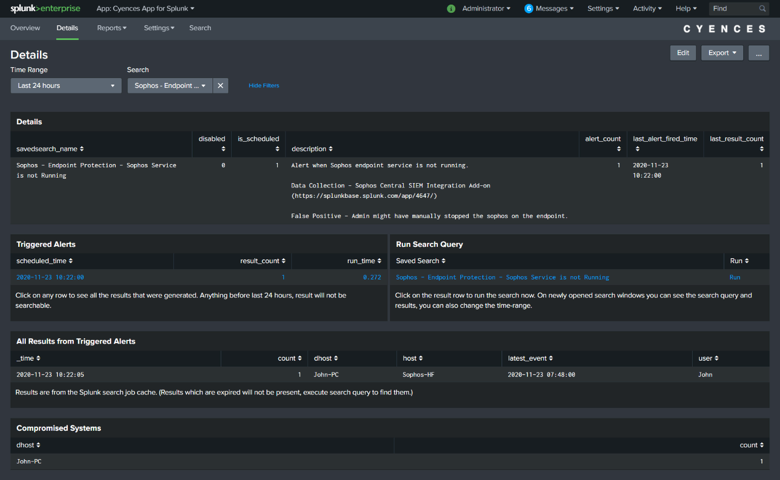
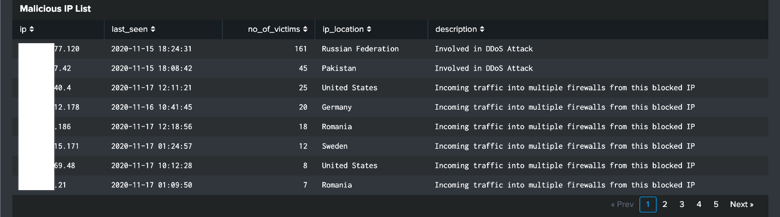
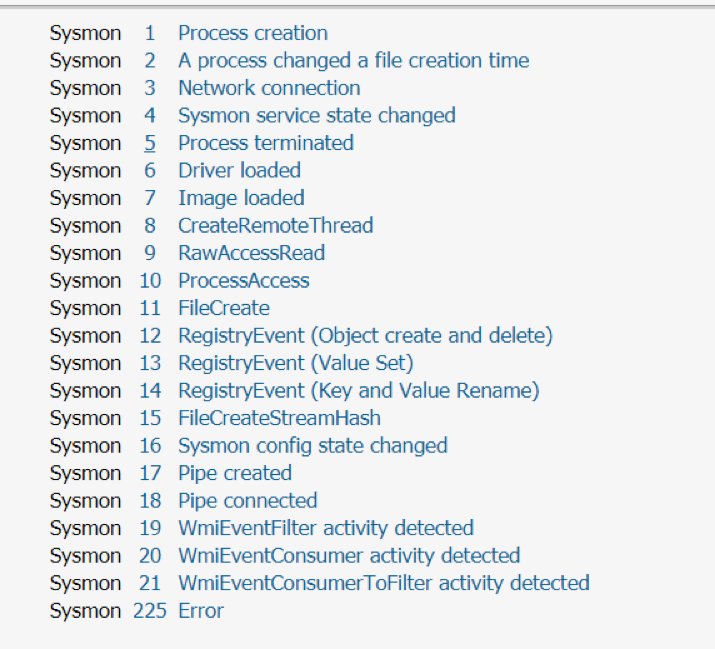
Since the beginning of the COVID-19 lockdown, we have witnessed an astonishing amount of attacks launched against remote workers. More and more companies have begun to pay perpetrators through a financial windfall that have allowed them to add more programmers to launch even more sophisticated attacks. Ransomware has become a full-on war than a skirmish.
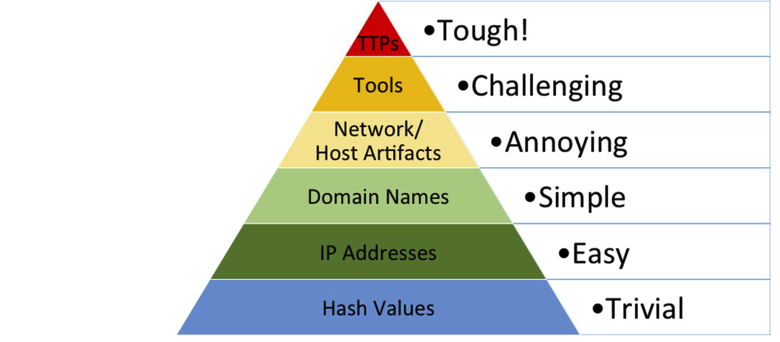
Although there is no magic bullet to achieve resolution, we can utilize existing technologies to prevent and slow this parallel epidemic. Our focus is on addressing the entire pyramid of pain (David Bianco) and will be creating solutions for each level although not in any specific order.
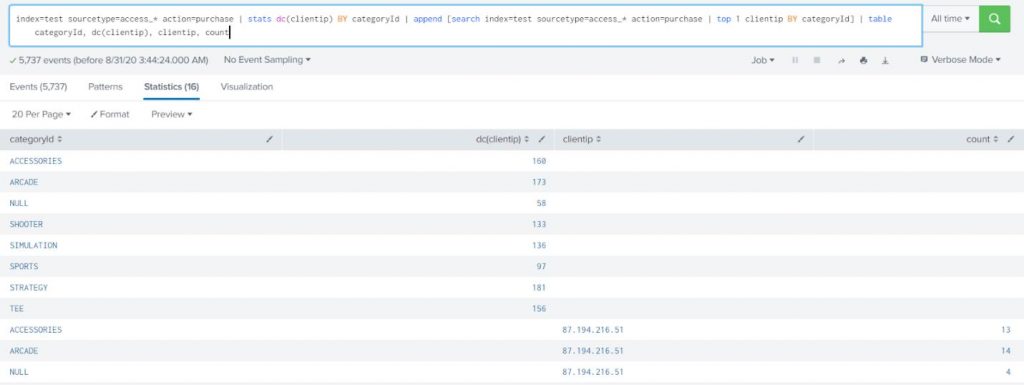
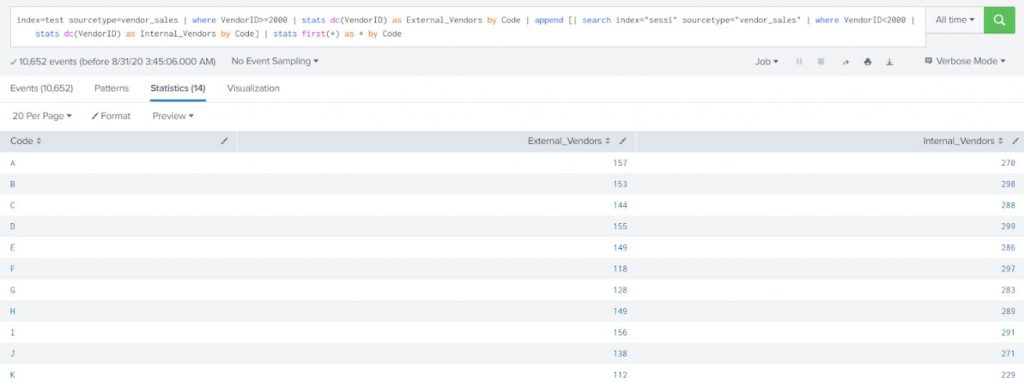
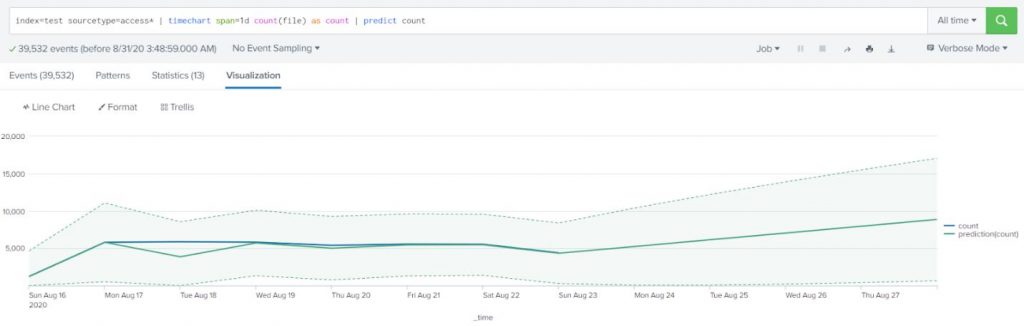
For this post, we will start putting together the orchestration tools available on Splunk to detect common patterns that ransomware follows, looking specifically for this blog at four key tactics (Common File Extensions, Common Ransomware notes, High number of file writes, and wineventlogclearing) These are based on MITRE ATT&CK ransomware detection techniques. If you work in this field, we welcome your opinion and insights.
Search macros are reusable chunks of Search Processing Language (SPL) that you can insert into other searches. Search macros can be any part of a search, such as an eval statement or search term, and do not need to be a complete command. You can also specify whether the macro field takes any arguments.

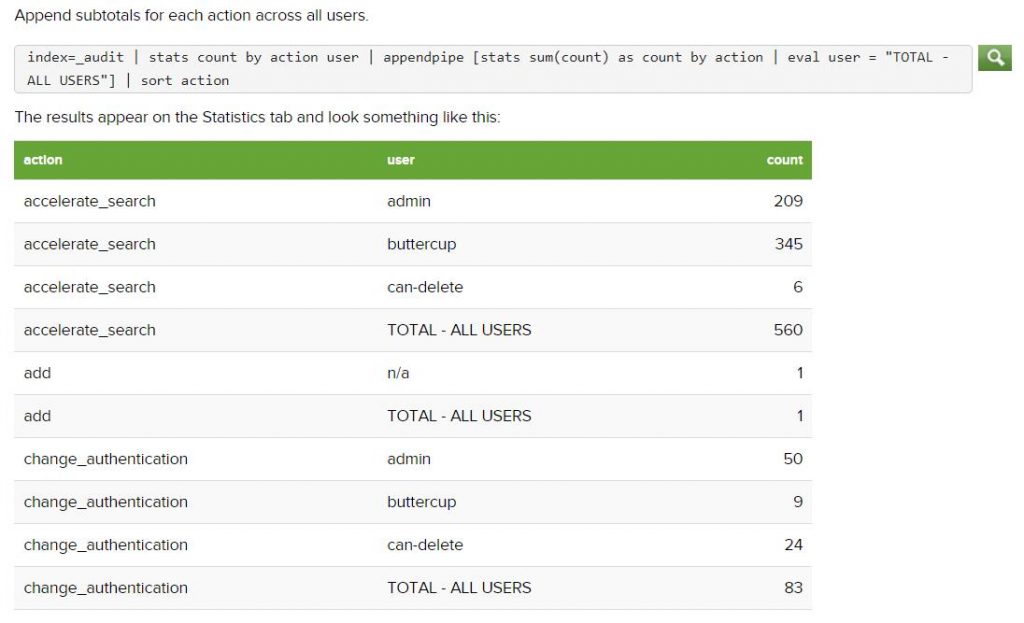
For this blog, we are going to go over how to ingest our windows environment and Active Directory logs and how to set up advanced search commands to continue with our efforts to reduce our attack surface area. This issue has gained importance since last week after the discovery of a new set of exploits that Microsoft cannot seem to be able to patch in time and instead is installing workarounds. Splunk is a great tool in these scenarios because you can create real-time alerts that would discover and mitigate automatically all the time.
Splunk Add-on for Windows will allow you to collect all the data related to Active Directory and Windows Event Logs.
Download from Splunkbase | Documentation
The Splunk App for Windows Infrastructure is a very good way to see your Windows and AD data. The App is created by Splunk.
Download | Documentation
You have to follow the step-by-step wizard within the App to configure the App.
Navigate to Splunk UI and Open the Splunk App for Windows Infrastructure.

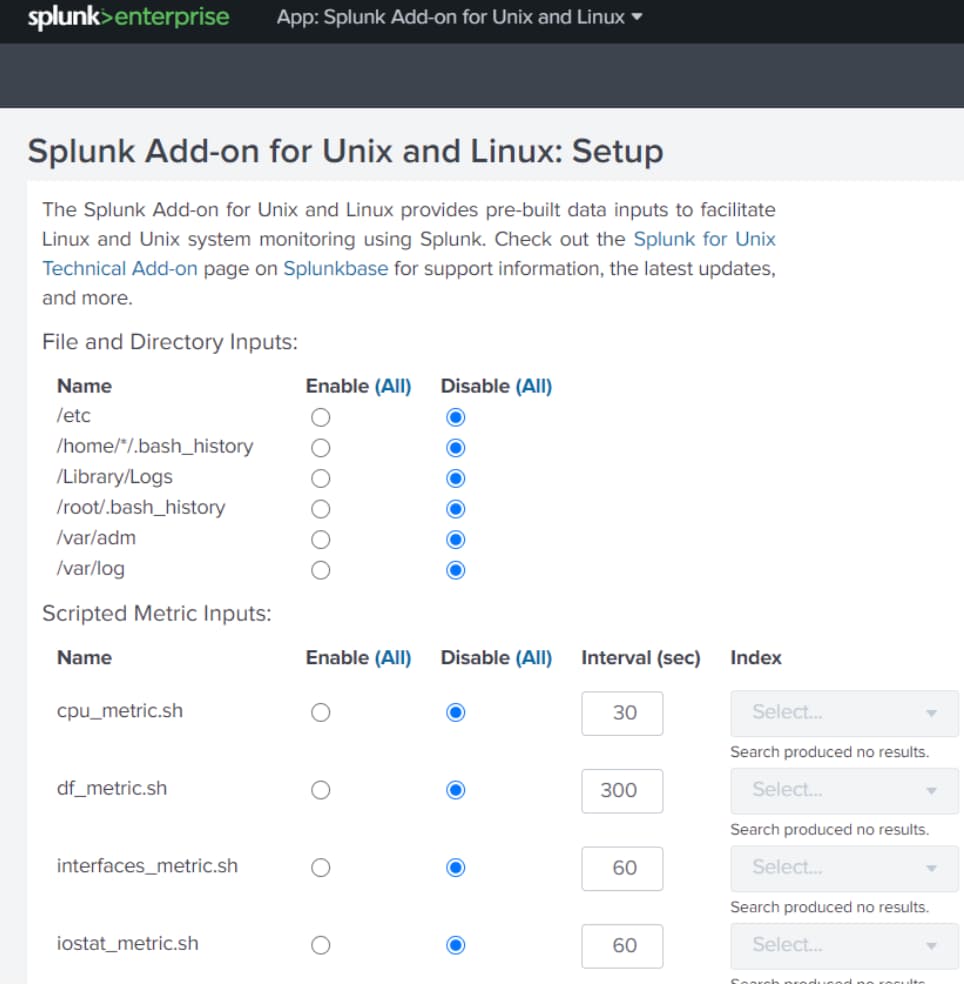


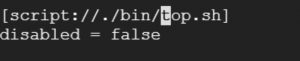
Add the below line in the stanza.
index = os
Your final stanza would look like:
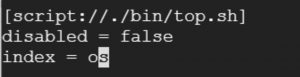
Save the file.
Restart Splunk.
Login to Splunk Web UI.
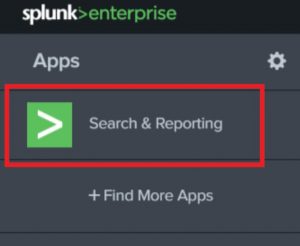
You will see a list of App on the left sidebar when you login. Open the Search & Reporting App.
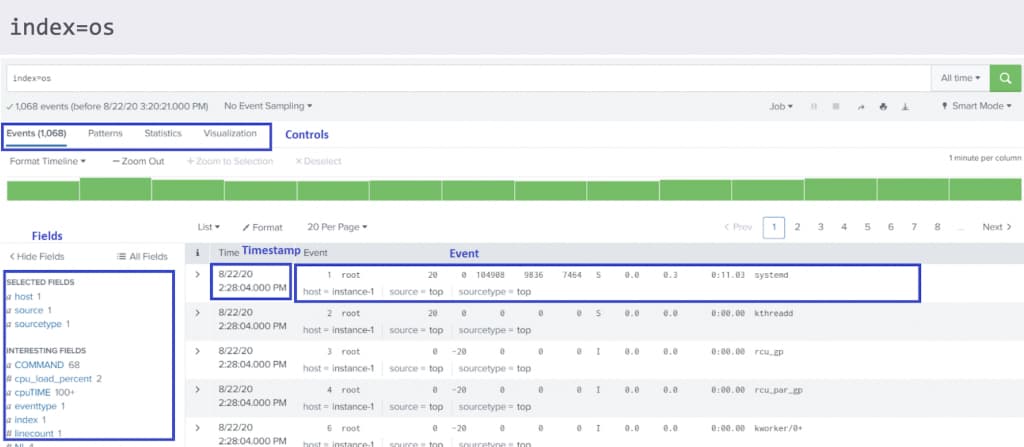
Let’s understand the main search part.

Search Bar – Where you will be writing SPL queries.
Time Range Picker – Each event (log) in Splunk has a timestamp, you can limit the time of your search with timerange picker.
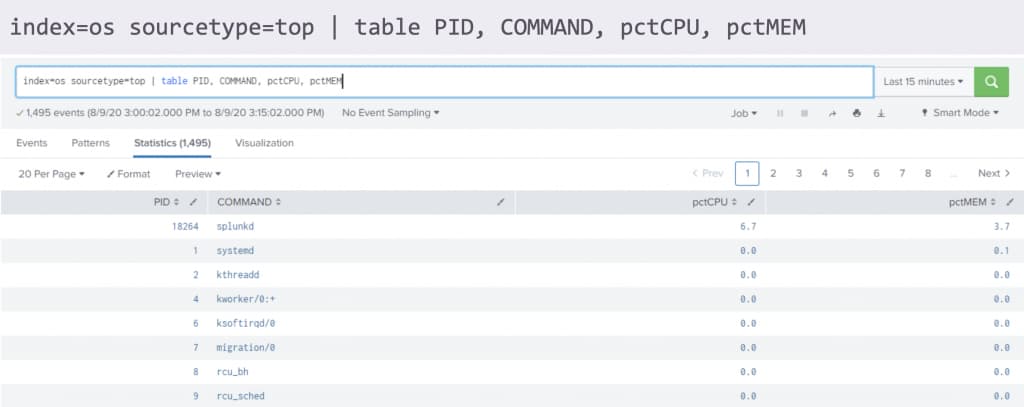
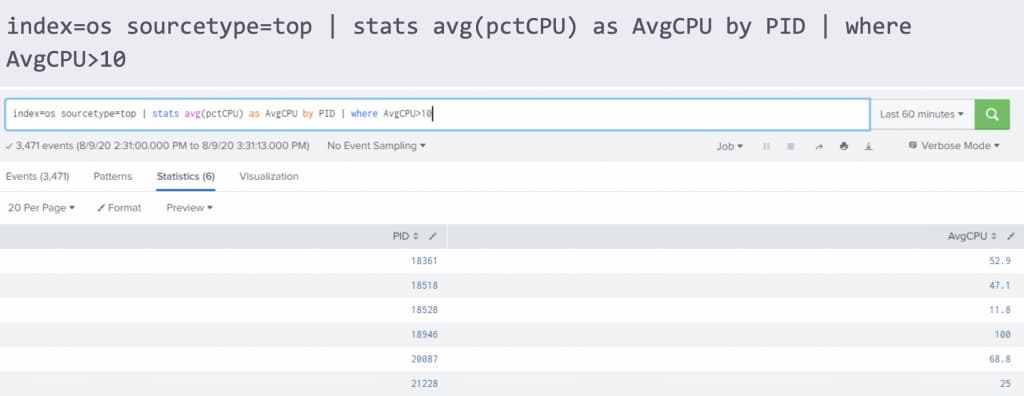
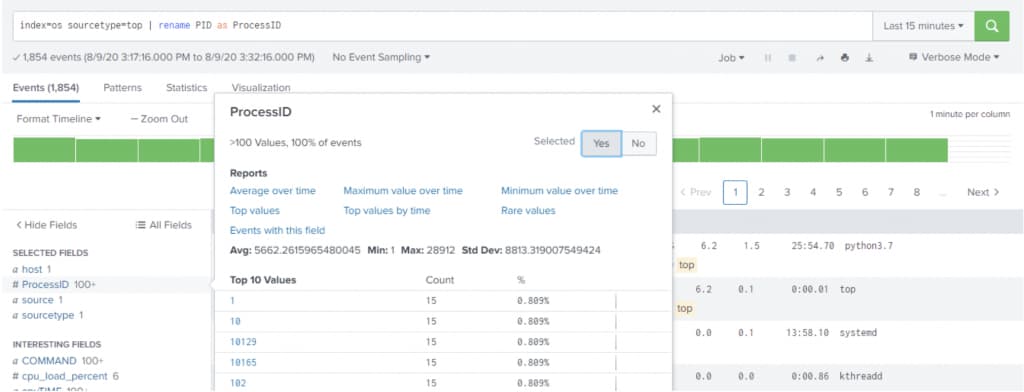
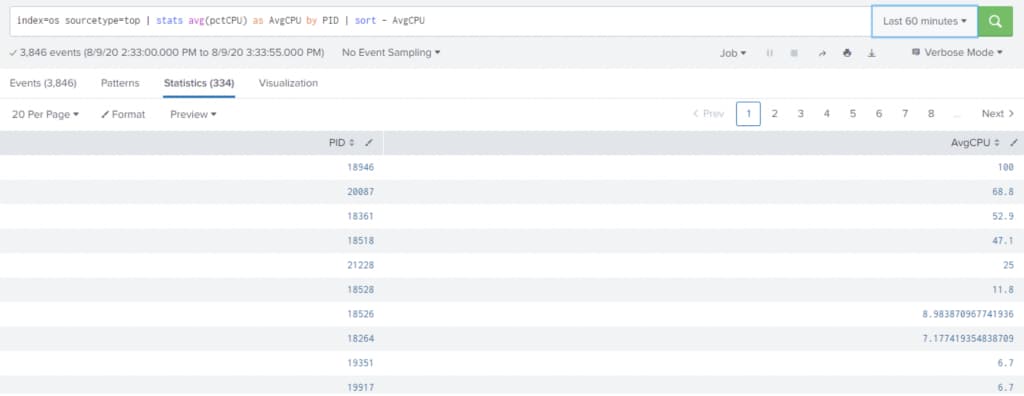
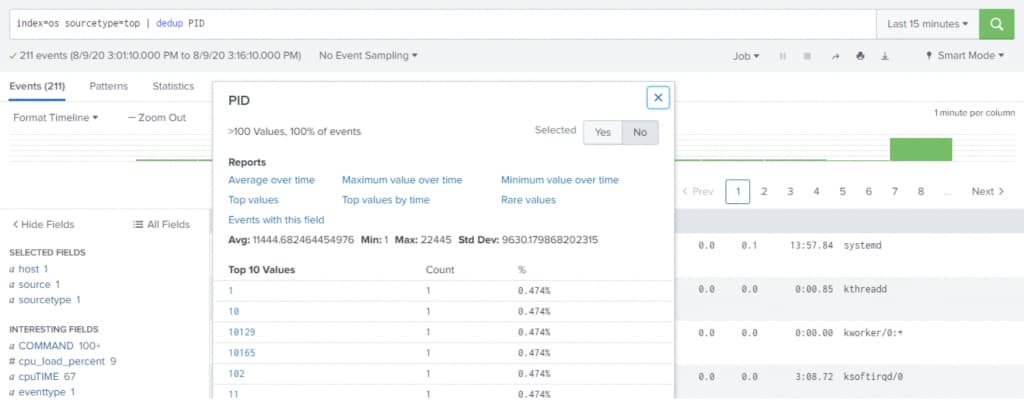
Add below search in the search bar and hit enter.
index=os |

You should not push any Apps individually onto an indexer. Instead, install and configure the Apps on the cluster master node and then push the changes to all the indexers. The following is the common configuration space on the master node-ster-![]()
How to push the configuration changes to the indexers:
Go to Master node UI.
Go to Settings > Indexer Clustering.
Click Edit > Configuration Bundle Actions.
(Optional) Click Validate and Check Restart > Validate and Check Restart.
It is recommended to validate the bundle before pushing it to the indexers.
Click Push.
Click Push Changes.
Where to find the configuration on the individual indexers?
![]()
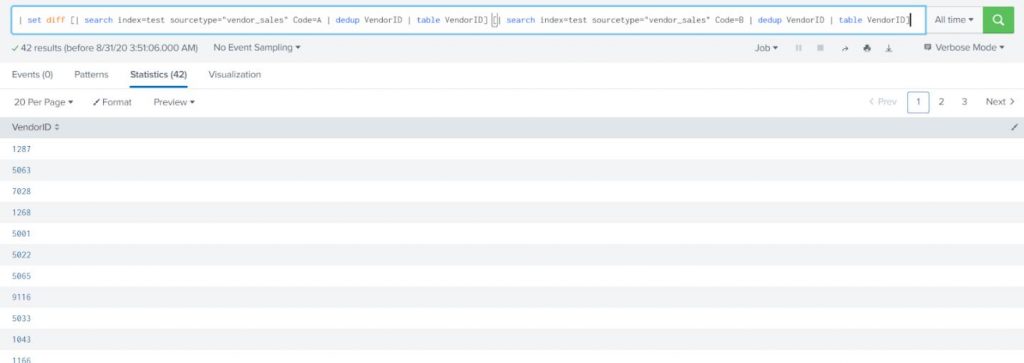
One thing that you will end up running into is the fact that over time, you will need to remove and add many indexes in your environment and to manage and edit those within each App is daunting. Instead, I recommended having an app called master_indexes (You can have any other name) and put an indexes.conf file in the local directory of this App and place all the indexes definitions in this file. Please note, if you enabled replication (see below)
add the following line to each index “ repFactor = auto” in all the stanzas of indexes.conf to tell Splunk to replicate the index across the cluster.
Follow all the steps of making a Splunk Instance as Search head including forwarding data to the indexers. See the section above- Search Head
Install Licence
Go to Settings > Licensing.
Click Add License.
Click Choose File. Browse for your license file and select it.
Click Install.
Follow the steps below on all the other instances in the cluster including the Master Node.
Navigate to Settings > Licensing.
Click Change to Slave.
Switch the radio button from Designate this Splunk instance as the Master License Server to designate a different Splunk instance as the Master License Server.
Specify the License Master to which this License Slave should report. You must provide either an IP address or a hostname, as well as the Splunk management port, which is 8089 by default.
Click Save.
Restart Splunk Enterprise.
Install Splunk.
Go to Splunk Web.
Settings > Indexer Clustering.
Select Enable Indexer Clustering.
Select the Search Head Node and click Next.
There are a few fields to fill out:
Master URI – https://:8089
Security key – Security Key is the key that you specified while configuring the Master Node.
Click Enable Search Head Node.
Restart Splunk.
Follow all the steps of making a Splunk Instance as Search head. See the section above: Search Head
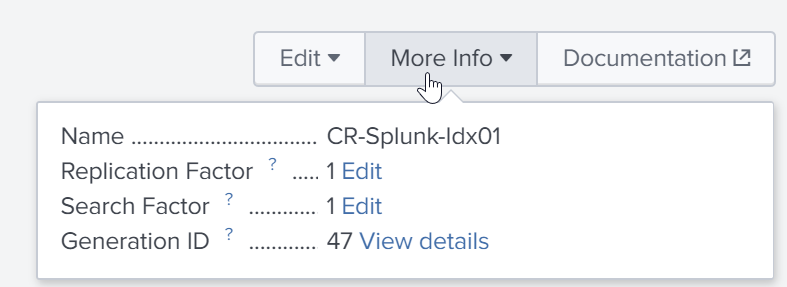
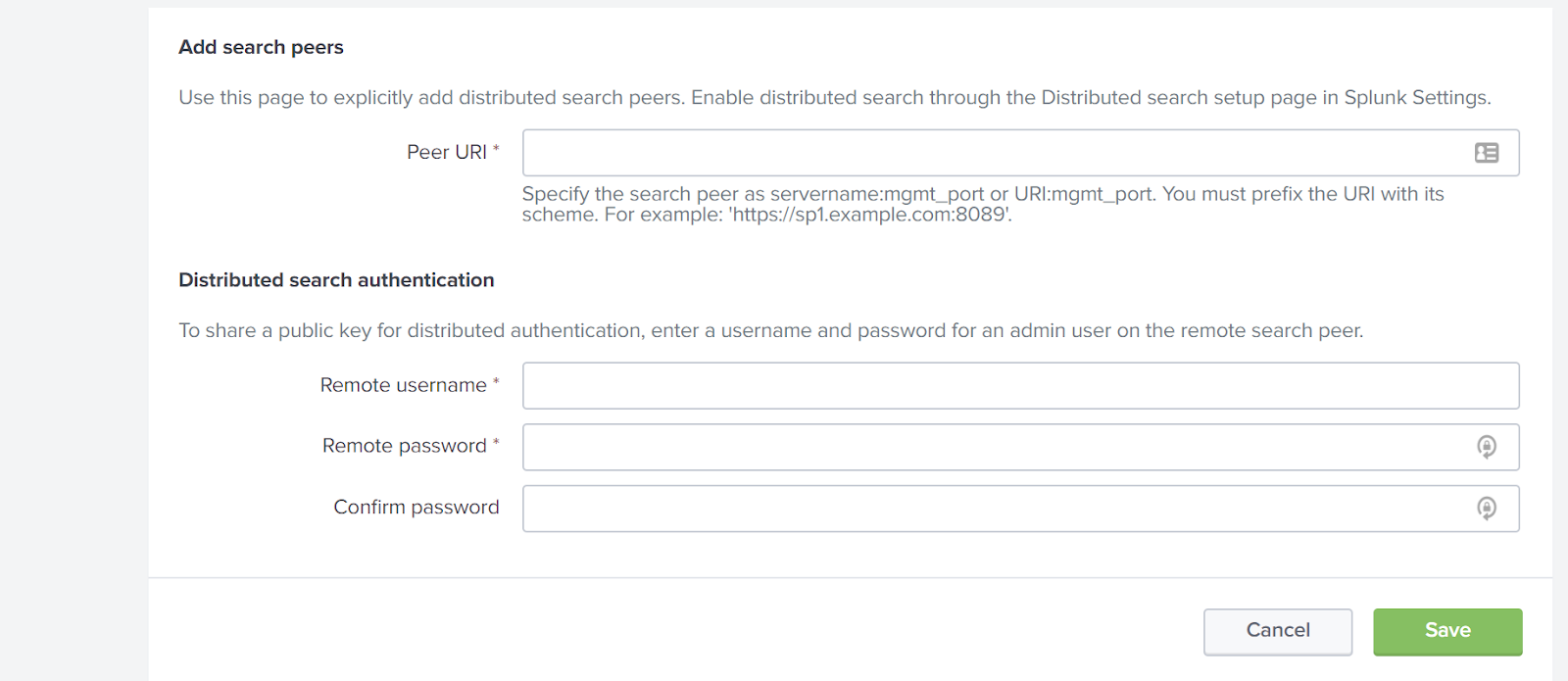
Navigate to Settings > Distributed search > Search peers.
Click New.
Fill in the requested fields (see below and click Save)
Repeat steps 3 and 4 for each search head, deployment server, license master, and cluster master.
Navigate to Settings > Monitoring Console.
Go to Settings > General Setup.
Click Distributed Mode.
Confirm the following:
The columns labeled instance and machine are populated correctly and show unique values within each column.
The server roles are correct. For example, a Search Head that is also a Licensed Master must have both server roles listed. If not, click Edit > Edit Server Roles and select the correct server roles for the instance.
Make sure the cluster master instance is set to the cluster master server role. If not, click Edit > Edit Server Roles and select the correct server role.
Make sure anything marked as an indexer is actually an indexer.
Click Apply Changes.
You can add the DMC and or License Master to any machine that is not under a heavy usage load.
Do not enable any other management tasks on the Cluster Master Node as it has the heavy load of managing the cluster.
Sometimes in a clustered environment, the search head is used to collect data from a cloud tenancy (through an App or TA), however, that data will not make its way to the indexers which will make it unsearchable by other search heads. The correct way to address that is by forwarding any data the search head collects to the Indexers.
Create an outputs.conf file in the![]()
Put the below content in the file.
# Turn off indexing on the node
[indexAndForward]
index = false
[tcpout]
defaultGroup = my_peers_nodes
forwardedindex.filter.disable = true
indexAndForward = false
[tcpout:my_peers_nodes]
server=10.10.10.1:9997,10.10.10.2:9997,10.10.10.3:9997
Here, replace IP addresses with the IP addresses of Indexers.
Any questions, comments, or feedback are appreciated! Leave a comment or send me an email to uhoulila@newtheme.jlizardo.com for any questions you might have.

In the past few blogs, I wrote about which environments to choose whether – clustered or standalone, how to configure on Linux, how to manage the storage over time, and the deployment server.
If you haven’t read our previous blogs, get caught up here! Part 1, Part 2, Part 3, Part 4
For this blog, I decided to switch it around and provide you with a CheatSheet (takes me back to high school) for the items that you will need through your installation process which are sometimes hard to find.
This blog will be split into two sections: Splunk and Linux CheatSheets
$SPLUNK_HOME$/bin/splunk status – To check Splunk status
$SPLUNK_HOME$/bin/splunk start – To start the Splunk processes
$SPLUNK_HOME$/bin/splunk stop – To stop the Splunk processes
$SPLUNK_HOME$/bin/splunk restart – To restart the Splunk
Go to “Settings” > “Licensing”.
For a more detailed report go to “Settings” > “Monitoring Console” > “Indexing” > “Licence Usage”
Clean Index Data (Note: you cannot recover these logs once you issue the command)
$SPLUNK_HOME$/bin/splunk clean eventdata -index
If you do not provide -index argument, that will clear all the indexes.
Do to apply this command directly in the clustered environment.
Click on your username on the top navigation bar and select “Preferences”.

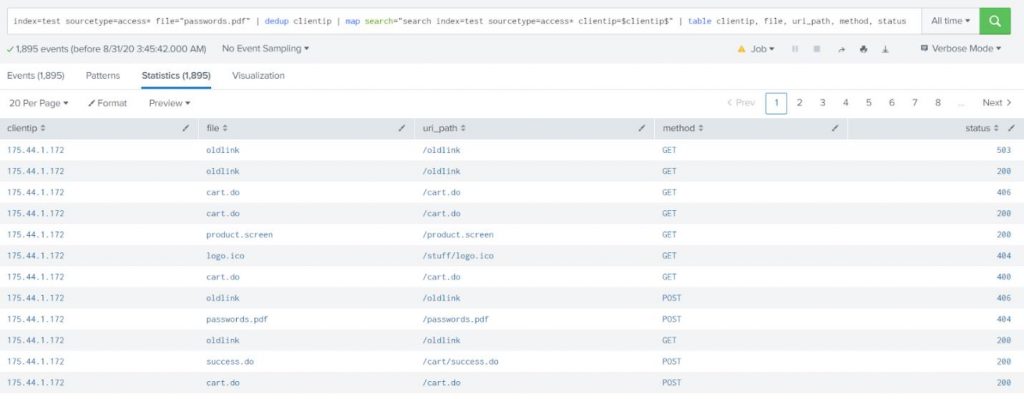
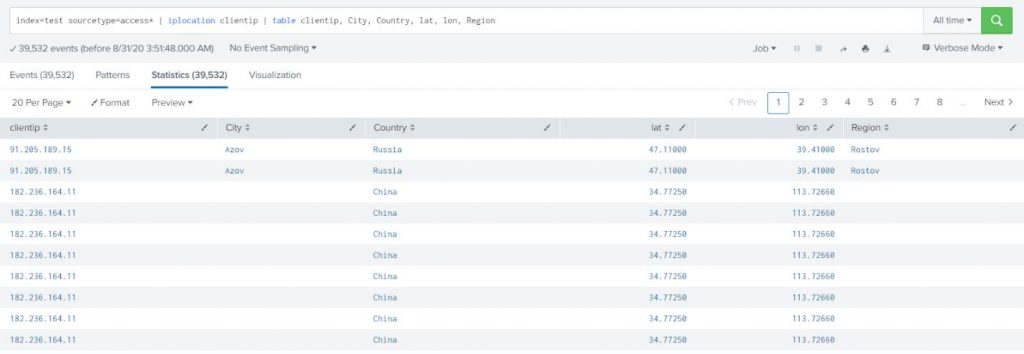
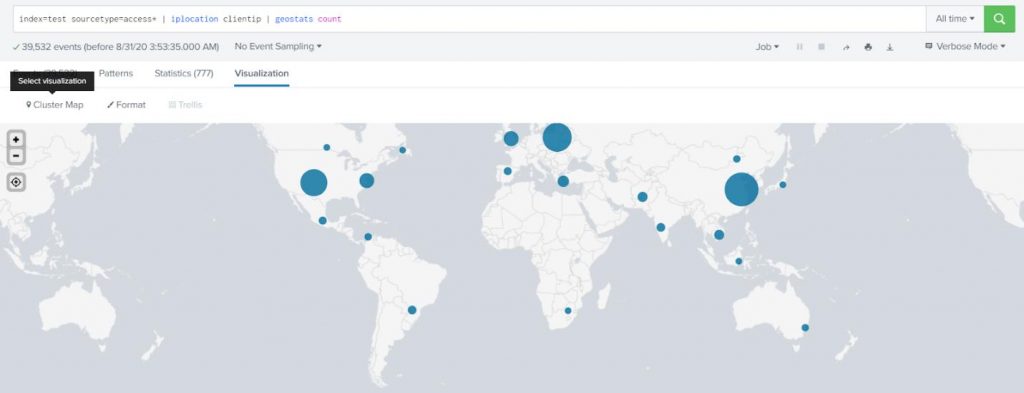
Index=”name of index you’re trying to search. E.g “pan_log” for Palo Alto firewalls”
Sourcetype=”name of sourcetype for the items you are looking for. E.g. “pan:traffic, pan:userid, pan:threat, pan:system”

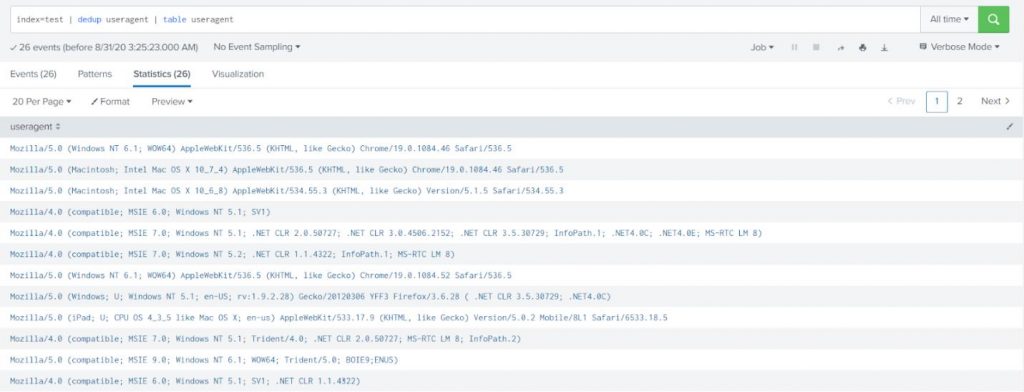
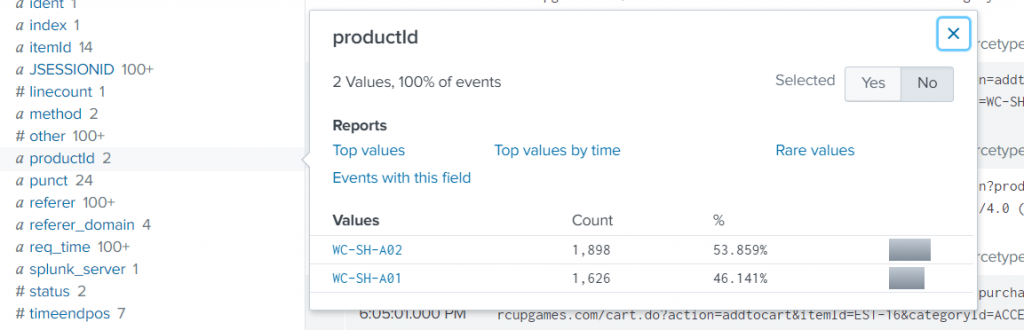
| dedup : allows you to remove all events of similar output – for instance if you dedup on user and your firewall is generating logs for all user activity, you will not see all the activity of the user, just all the distinct users

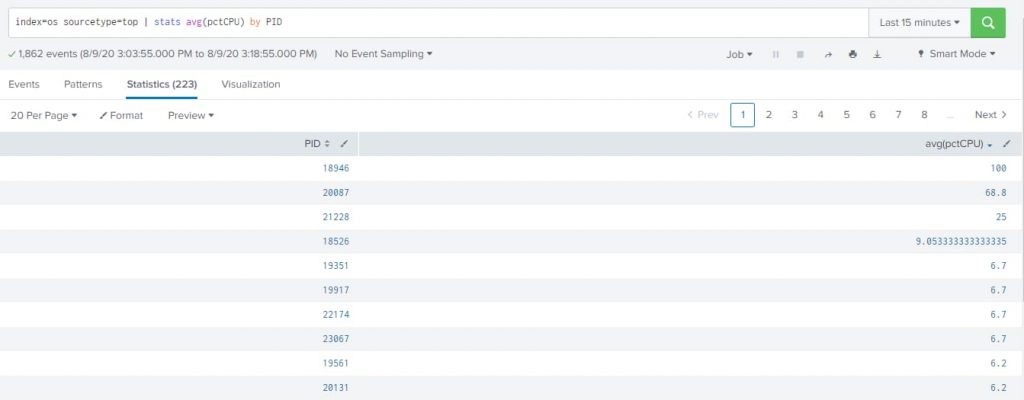
| stats: Calculates aggregate statistics, such as average, count, and sum, over the results set
| stats count by rule : Will show you the number of events that matches any specific rule on your firewall

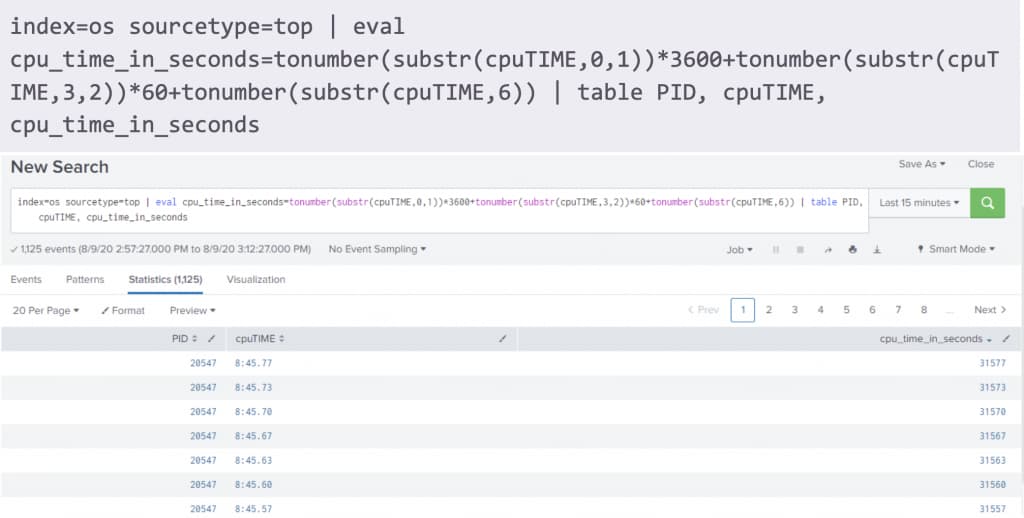
As most of you may know, the _time field in the events in Splunk is not always the event ingestion time. So, how to get event ingestion time in Splunk? You can get that with the _indextime field.
| eval it=strftime(_indextime, “%F %T”) | table it, _time, other_fields

index=_internal source=*metrics.log tcpin_connections or udpin_connections


whoami – Which user is active. Useful to verify you are using the correct user to make configuration changes in the backend.
chown -R : – Change the owner of directory.
mv – Moving file or directory to new location.
mv – Renaming a file or directory.
cp – Copy a file to a new location.
cp -r – Copy a directory to the new location.
rm -rf – Remove file or directory.
df -h – Get disk usage (in human-readable size unit)
du -sh * – Get the size of all the directories under the current directory.
watch df -h – Monitor disk usage (in human-readable size unit). Update stats every two seconds. Press Ctrl+C to exit.
watch du -sh * – Get size of all the directories under the current directory. Update stats every two seconds. Press Ctrl+C to exit.
ps -aux – List all the running processes.
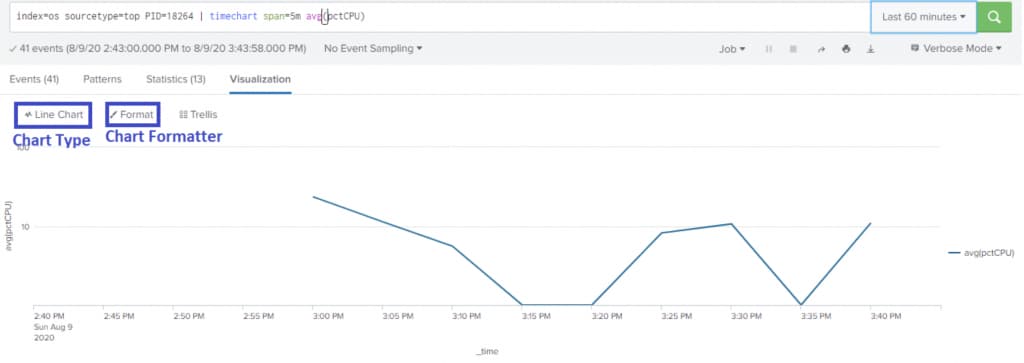
top – Get resource utilization statistics by the processes
vi – Open and edit the file with VI editor
tail -f – Tail the log file (will display the content of the log file. Unlike cat, touch, or vi it displays the live logs coming to the file.
ifconfig – To get the IP address of the machine
Any questions, comments, or feedback are appreciated! Leave a comment or send me an email to uhoulila@newtheme.jlizardo.com for any questions you might have.

Thank you for joining us for part four of our ABC’s of Splunk series. If you haven’t read our first three blogs, get caught up here! Part 1, Part 2, Part 3.
When I started working with Splunk, our installations were mostly small with less than 10 servers and the rest of the devices mainly involved switches, routers, and firewalls. In the current environments which we manage most installations have more than three hundred servers which are impossible to manage without some form of automation. As you manage your environment over time, one of the following scenarios will make you appreciate the deployment server:
A deployment server is an easy way to manage forwarders without logging into them directly and individually to make any changes. Forwarders are the Linux or Microsoft Windows servers that you are collecting logs from by installing the Splunk Universal Forwarder.
Deployment servers also provide a way to show you which server has which Apps and whether those servers are in a connected state or offline.
Please note that whether you use Splunk Cloud or on-prem, the Universal Forwarders are still your responsibility and I hope that this blog will provide you with some good insights.
The below image shows how a deployment architecture looks conceptually.

There are three core components of the deployment server architecture:
The recommendation is to use a dedicated machine for the Deployment Server. However, you can use the same machine for other management components like “License Master”, “SH Cluster Deployer” or “DMC”. Do not combine it with Cluster Master.
I started writing this in a loose format explaining the concepts but quickly realized that a step by step is a much easier method to digest the process
By default, a Splunk server install does not have the deployment server configured and if you were to go to the GUI and click on settings, forwarder management, you will get the following message.

To enable a deployment server, you start by installing any App in $SPLUNK_HOME/etc/deployment-apps directory. If you’re not sure how to do that, download any App that you want through the GUI on the server you want to configure (see the example below)

and then using the Linux shell or Windows server Cut/Paste, mv the entire App directory that was created from $SPLUNK_HOME/etc/apps where it installs by default to $SPLUNK_HOME/etc/deployment-apps. See below:
Move
/opt/splunk/etc/apps/Splunk_TA_windows$
To /opt/splunk/etc/deployment-apps/Splunk_TA_windows$
This will automatically allow your Splunk server to present you with the forwarder management interface
Next, you will need to add a server class. Go to Splunk UI > Forwarder Management > Server Class. Create a new server class from here.


Give it a name that is meaningful to you and your staff and go to Step 3
You can either specify that in the GUI guided config when you install Splunk Universal Forwarder on a machine or by using the CLI post installation
Splunk set deploy-poll <IP_address/hostname>:
Where,
IP_Address – IP Address of Deployment Server
management_port – Management port of deployment server (default is 8089)
Go to any of the server classes you just created, click on edit clients.


For Client selection, you can choose the “Whitelist” and “Blacklist” parameters. You can write a comma-separated IP address list in the “Whitelist” box to select those Clients
Go to any of the server classes you just created, and click on edit Apps.

Click on the Apps you want to assign to the server class.

Once you add Apps and Clients to a Server Class, Splunk will start deploying the Apps to the listed Clients under that Server Class.

You will also see whether the server is connected and the last time it phoned home.

Note – Some Apps that you push require the Universal Forwarder to be restarted. If you want Splunk Forwarder to restart on update of any App, edit that App (using the GUI) and then select the checkbox “Restart on Deploy”.

You have a few AD servers, a few DNS servers and a few Linux servers with Universal Forwarders installed to get some fixed sets of data, and you have 4 separate Apps to collect Windows Performance data, DNS specific logs, Linux audit logs, and syslogs.
Now you want to collect Windows Performance logs from all the Windows servers which includes AD servers, and DNS servers. You would also like to collect syslog and audit logs from Linux servers.
Here is what your deployment server would look like:
Go to the Search Head and search with the below search (Make sure you have rights to see internal indexes data):
index=_internal | dedup host | fields host | table host
Look in the list to see if your Forwarder’s hostname is in the list, if it is present that means the Forwarder is connected. If you are missing a host using the above command, you might have one of two problems:
If you are missing a particular index/source data then check inputs.conf configuration in the App that you pushed to that host.
Protect content during App updates (A must-read to minimize the amount of work you have to do overtime managing your environment)
https://docs.splunk.com/Documentation/Splunk/8.0.5/Updating/Excludecontent
Example on the Documentation
Any questions, comments, or feedback are appreciated! Leave a comment or send me an email to uhoulila@newtheme.jlizardo.com for any questions you might have.